Elon Musk is planning to start a colony on Mars. Jason Torchinsky proposed some improvements to Musk’s proposed spaceship design, but some commenters on social media questioned Torchinsky’s proposals. I’ve reproduced these comments below, so that I can link to them more easily.
Amateur rocket engineer Evan Daniel writes:
1) I’m not sure how luxurious the actual craft will be. It should clearly be more luxurious than Apollo, to keep the passengers sane. But it being more spartan than Elon was talking about, especially early, seems likely.
2) Elon clearly likes the simplicity of only one upper stage hull design. The cargo, passenger, and fuel versions share a hull. This makes a great deal of sense for version one to me. Adding a second, third, or fourth major ship type is for later.
2a) If the author is keen on their hab module thing, they might as well go all the way to a cycler, which plenty of other people have talked about. I’m confused by them not mentioning this along with the L1 garage idea, given that it should further save propellant.
3) That means you don’t actually want to shrink the passenger ship. Sure you could build everything, first stage and fuel stages included, to a smaller scale… but the large scale is part of why it will be cheap per passenger or per pound. So “more spartan” translates as “more passengers” or “more cargo on board”, not “smaller ship”.
3a) That combined with number 2 might mean that open space is weirdly cheaper than you’d think. I’d have to investigate in more detail (aka break out the spreadsheets) to be sure. I’m not certain on this. (Mass for stuff is definitely still as pricey as you think, but the passenger version might have “too much volume” because the fuel-carrying version needs it for tanks and they share a hull.)
4) On-orbit transfer of people is complicated. Propellant transfer is far less so. The ITS as proposed is actually a very conservative design in some ways; these changes are less so. In particular they cost development money in an attempt to save operating costs, while making operations more complex. This seems misguided, given that SpaceX is probably short on funds for development (relatively speaking). Before you call for making operations more complex, think hard about the F9H schedule slips (while noting that F9H should be cheaper per pound launched than F9).
Anyway, I definitely don’t have enough info to say who is right. But I definitely know enough to think these proposed changes are not obviously a good thing. Especially the parts that advocate for more complex development and operations in an attempt to reduce operating costs. I’ll put my money on the SpaceX crew mostly knowing what they’re talking about in this case. (I’d also put money on the ITS having meaningful changes from this before its first passenger-carrying Mars flight, but I suspect they won’t be the ones listed here.)
Or, more simply: the author didn’t pay enough attention to the most relevant slide of all:
The dominant cost of the flight to Mars is the ship that goes to Mars. Not the stage to launch it, not the other launches to fuel it. The dominant cost of that ship is the development and construction cost. If your “cost saving” measures are saving elsewhere by making that budget item bigger, you’re probably doing it wrong.
Well, one difficulty with the proposed “space only” module is that you cannot aerobrake with it. The proposed Muskian solution is to aerobrake as you’re entering the Mars atmosphere, and decrease overall fuel requirements thus for going from Earth to Mars; you can also aerobrake when entering Earth’s atmosphere, and decrease fuel requirements for going from Mars to Earth. So that’s a big cost. This solution will require fuel for braking while going Earth to Mars, and Mars to Earth, for both the hab and the lander.
Someone raises this point in the comments, and [Torchinsky] says, “throw an aerobraking shell on it,” but I’m not sure it’s that simple. An inflatable structure designed for zero g–which is the whole attraction of the concept–wouldn’t work well aerobraking, I’d guess.
The second difficulty is re fuel requirements. Decreasing aerobraking means that you’ll need more fuel for the Mars to Earth rendevous, and that makes me wonder if the smaller ship will have difficulty getting enough fuel through in-situ methane generation to both launch from Mars, push the larger structure to Earth, then brake the larger structure and itself so they’re in orbit. So you’re dealing with potentially (absolutely) increased fuel requirements, unless you can cut the mass by enough, while you’re also decreasing the amount of fuel you bring from the Martian surface.
Oh, re the concern with difficulty landing the ship on Mars–Mars dust storms are extremely weak (least accurate part of The Martian), compared to earth storms, so that would be no problem.
Suggestion re launching the tanker before the crewed ship–this has been raised, I think Musk has said they might do this, unsure of advantages and disadvantages.
Of course I’d need to do the math to really know anything about this.
And mathematician Jonathan Lee adds:
The Soyuz is lighter than the Apollo capsules because the Orbital and instrument modules did not have to be recovered successfully; they burned up on Earth entry. It’s an approach that’s useful when you do not need everything.
The object of the ITS is to, well, get one’s ass to Mars. The galleys, toilets etc. (which are not actually the main mass drivers but let us not have mere facts get in the way) need to get down onto the surface, at least until the crew have built out a bunch of extra infrastructure. This needs to go there. Fuel on Mars is pretty explicitly not precious; the entire architecture is based around solar driving electrolysis and Sabatier reactions to make fuel. You actually want the lander to have enough delta-V to push the entire Mars – Earth return stack back to Earth. Scale is actually important here. They are ultimately not trying to get minimum cost flags-and-footprints. They are trying to build an architecture that reliably moves 200-500 tonnes of stuff to Mars. That is the point. To get enough mass there that you can build a self sustaining colony in a place colder, dryer and with less atmosphere than Antarctica. They need the mass moved.
Oh, winds. Ha. Yeah, so the atmosphere on Mars is about 1% the density of that of Earth. Wind forces go like the square of velocity, so you can convert Mars winds to Earth winds by dividing velocity by 10. The highest wind speeds that I can find reported for Mars are about 90mph (solid hurricane territory). So the dynamic pressures are about that of a 10mph wind on Earth. So, no, wind is not a problem.
The in-transit model being proposed cannot aerobrake, cannot even pretend to provide radiation protection, and means that now you need to have orbital assembly at both Mars and Earth on every launch. Oh, and have those docked connections take the not-inconsiderable forces of the injection burns each way.
I asked aerospace engineer Lloyd Strohl III to review this post, and he affirmed that Daniel and Lee’s comments here look correct.
I try to watch out for inconsistencies in my beliefs (and between my actions and my stated beliefs and goals). Yet I’m not a fan of criticizing people for things like “hypocrisy.”
It’s obviously a personal attack, and personal attacks obviously make people defensive, and defensiveness is obviously boring and terrible. But I have four other concerns with attacking people for their inconsistencies:
1. It’s too meta. Proving that someone said “p” and “not-p” is a great way to conclusively defeat them in a debate. No matter what your audience believes about p, they’ll agree with you about the laws of logic; and by not entering the fray, you get to appear impartial and objective.
But the fray matters — or if it doesn’t matter, why are we talking about p in the first place?
“You said ⊥!” is an amazing argument that works no matter what the facts are. For that reason, it’s an amazing argument that tells us nothing about the world, aside from ad-hominem facts about the claimant’s character.
If someone is saying both “p” and “not p,” then at least one of those views is false. If you know which of those views is false, why not just attack the false view? If you don’t know which of those views is false, why not talk that over and try to figure it out? If figuring it out matters less than scoring points against Ms. Placeholder, then it’s possible that neither is worth your time.
2. Charges of hypocrisy discourage updating and nuance. The easiest way to look consistent over time is to assert simple blanket statements and then refuse to change your mind about them. Better yet, say nothing substantive at all.
It’s sometimes important to publicly evaluate others’ character. In a presidential debate, for example, “ad hominem” is not always a fallacy. We’re trying to assess which person is more trustworthy and competent, not just which one is more correct; the personal virtues and vices of the candidates matter.
Yet even in this context, “Senator Placeholder is wrong on taxes” is much more useful than “Senator Placeholder is inconsistent on taxes.” Debate the latter, and the candidates and their audience only learn new things about a particular senator’s record, not about taxes; and Placeholder’s immediate incentive is to obfuscate her views or make them as simple and unchanging as possible, rather than to improve or defend them.
3. In the case of groups, charges of hypocrisy discourage intellectual diversity. This is one of the problems I have with the “motte and bailey” idea: by attacking groups for “strategically equivocating” between a more defensible view (the “motte”) and a less defensible one (the “bailey”), we neglect the more common case where some people honestly have less defensible versions of their friends’ views.
By attacking the hypocrisy rather than attacking the false view, we again focus the debate on people’s faults and vices. In this way, the motte/bailey accusation increases the number of debates that are about how generally “good” or “bad” a group is, to the exclusion of mundane empirical questions.
The motte/bailey charge can be useful when a particular individual explicitly states both the motte and the bailey, though even then it’s a charge best reserved for friends and not enemies. But when two different individuals can be accused of Emergent Hypocrisy merely for associating with each other, it becomes a lot harder to associate with anyone who doesn’t share all your views.
4. Ambitious goal-setting and self-improvement can look like behavioral hypocrisy. Accusing someone of hypocrisy because their deeds don’t live up to the moral principles they endorse encourages people to have low, easily-met standards.
We’re already risk-averse, and the charge of hypocrisy makes risk-taking even riskier, especially for groups. Trying to build a community that exemplifies certain virtues often requires that you talk quite a bit about those virtues. But then you risk looking like you already think you have those virtues.
Even if your community is a standard deviation above most groups in the virtue of Temperance, the mere fact that you’ve endorsed Temperance means that any small misstep by anyone in your group can be used to charge you with hypocrisy or hubris. And hypocrisy and hubris are approximately people’s favorite things to accuse each other of. Easier, then, to steer clear of endorsing good ideas too loudly.
I’ve said before that my favorite blog — and the one that’s shifted my views in the most varied and consequential ways — is Scott Alexander’s Slate Star Codex. Scott has written a lot of good stuff, and it can be hard to know where to begin; so I’ve listed below what I think are the best pieces for new readers to start with. This includes older writing, e.g., from Less Wrong.
The list should make the most sense to people who start from the top and read through it in order, though skipping around is encouraged too — many of the posts are self-contained. The list isn’t chronological. Instead, I’ve tried to order things by a mix of “where do I think most people should start reading?” plus “sorting related posts together.” If stuff doesn’t make sense, you may want to Google terms or read background material in Rationality: From AI to Zombies.
This is a work in progress; you’re invited to suggest things you’d add, remove, or shuffle around.
Back in November, I argued (in Inhuman Altruism) that rationalists should try to reduce their meat consumption. Here, I’ll update that argument a bit and lay out some of my background assumptions.
Unfortunately for cows, I think there is an approximately 0% chance that hurting cows is (according to my values) just as bad as hurting humans. It’s still bad – but its badness is some quite smaller number that is a function of my upbringing, cows’ cognitive differences from me, and the lack of overriding game theoretic concerns as far as I can tell.
I’m actually pretty much OK with animal suffering. I generally don’t empathize all that much, but there a lot of even completely selfish reasons to be nice to humans, whereas it’s not really the case for animals.
My primary audience was rationalists who terminally care about reducing suffering across the board — but I’ll admit I thought most LessWrong users would fit that description. I didn’t expect to see a lot of people appealing to their self-interest or their upbringing. Since it’s possible to pursue altruistic projects for selfish reasons (e.g., attempting to reduce existential risk to get a chance at living longer), I’ll clarify that my arguments are directed at people who do care about how much joy and suffering there is in the world — care rather a lot.
The most detailed defense of meat-eating was Katja Grace’s When should an effective altruist be vegetarian? Katja’s argument is that egalitarians should eat frugally and give as much money as they can to high-impact charities, rather than concerning themselves with the much smaller amounts of direct harm their dietary choices cause.
Paul Christiano made similar points in his blog comments: if you would spend more money sustaining a vegan diet than sustaining a carniferous diet, the best utilitarian option would be for you to remain a meat-eater and donate the difference.
Most people aren’t living maximally frugally and giving the exactly optimal amount to charity (yet). But the point generalizes: If you personally find that you can psychologically use the plight of animals to either (a) motivate yourself to become a vegan for an extra year or (b) motivate yourself to give hundreds of extra dollars to a worthy cause, but not both, then you should almost certainly choose (b).
My argument did assume that veganism is a special “bonus” giving opportunity, a way to do a startling amount of good without drawing resources from (or adding resources to) your other altruistic endeavors. The above considerations made me shift from feeling maybe 80% confident that most rationalists should forsake meat, to feeling maybe 70% confident.
To give more weight than that to Katja’s argument, there are two questions I’d need answered:
1. How many people are choosing between philanthropy and veganism?
Some found the term “veg*nism” (short for “veganism or/and vegetarianism”) confusing in my previous post, so I’ll switch here to speaking of meat-abstainers as “plant people” and meat-eaters as “meat people.” I’m pretty confident that the discourse would be improved by more B-movie horror dialogue.
Plant people have proven that their mindset can prevent a lot of suffering. And I don’t see any obvious signs that EAs’ plantpersonhood diminishes their EAness. To compete, Katja’s meat-person argument needs to actually motivate people to do more good. “P > Q > R” isn’t a good argument against Q if rejecting Q just causes people to regress to R (rather than advance to P).
What I want to see here are anecdotes of EAs who have had actual success trying “pay the cost of veganism in money” (or similar), to prove this is a psychologically realistic alternative and not just a way of rationalizing the status quo.
(I’m similarly curious to see if people can have real success with my idea of donating $1 to the Humane League after every meal where you eat an animal. Patrick LaVictoire has tried out this ritual, which he calls “beefminding“. (Edit 9/11: Patrick clarifies, “I did coin ‘beefminding’, but I use it to refer to tracking my meat + egg* consumption on Beeminder, and trying to slowly bend the curve by changing my default eating habits. I don’t make offsetting donations. What I’m doing is just a combination of quantified self and Reducetarianism.”))
If I “keep fixed how much of my budget I spend on myself and how much I spend on altruism,” Katja writes, plant-people-ism looks like a very ineffective form of philanthropy. But I don’t think most people spend an optimal amount on altruistic causes, and I don’t think most people who spend a suboptimal amount altruistically ought to set a hard upper limit on how much they’re willing to give. Instead, I suspect most people should set a lower limit and then ratchet that limit upward over time, or supplement it opportunistically. (This is the idea behind Chaos Altruism.)
If you’re already giving everything to efficient charities except what you need to survive, or if you can’t help but conceptualize your altruistic sentiment as a fixed resource that veganism would deplete, then I think Katja’s reasoning is relevant to your decision. Otherwise, I think veganism is a good choice, and you should even consider combining it with Katja’s method, giving up meat and doubling the cost of your switch to veganism (with the extra money going to an effective charity). We suboptimal givers should take whatever excuse we can find to do better.
Katja warns that if you become a plant person even though it’s not the perfectlyoptimal choice, “you risk spending your life doing suboptimal things every time a suboptimal altruistic opportunity has a chance to steal resources from what would be your personal purse.” But if the choice really is between a suboptimal altruistic act and an even less optimal personal purchase, I say: mission accomplished! Relatively minor improvements in global utility aren’t bad ideas just because they’re minor.
I could see this being a bad idea if getting into the habit of giving ineffectively depletes your will to give effectively. Perhaps most rationalists would find it exhausting or dispiriting to give in a completely ad-hoc way, without maintaining some close link to the ideal of effective altruism. (I find it psychologically easier to redirect my “triggered giving” to highly effective causes, which is the better option in any case; perhaps some people will likewise find it easier to adopt Katja’s approach than to transform into a plant person.)
It would be nice if there were some rule of thumb we could use to decide when a suboptimal giving activity is so minor as to lack moral force (even for opportunistic Chaos Altruists). If you notice a bug in your psychology that makes it easier for you to become a plant person than to become an optimally frugal eater (and optimal giver), why is that any different from volunteering at a soup kitchen to acquire warm fuzzies? Why is it EA-compatible to encourage rationalists to replace the time they spend eating meat with time spent eating plants, but not EA-compatible to encourage rationalists to replace the time they spend on Reddit with time spent at soup kitchens?
Part of the answer is simply that becoming a plant person is much more effective than regularly volunteering at soup kitchens (even though it’s still not comparable to highly efficient charities). But I don’t think that’s the whole story.
2. Should we try to do more “ordinary” nice things?
Suppose some altruistic rationalists are in a position to do more good for the world by optimizing for frugality, or by ethically offsetting especially harmful actions. I’d still worry that there’s something important we’re giving up, especially in the latter case — “mundane decency,” “ordinary niceness,” or something along those lines.
I think of this ordinary niceness thing as important for virtue cultivation, for community-building, and for general signaling purposes. By “ordinary niceness” I don’t mean deferring to conventional/mainstream morality in the absence of supporting arguments. I do mean privileging useful deontological heuristics like “don’t use violence or coercion on others, even if it feels in the moment like a utilitarian net positive.”
If we aren’t relying on cultural conventions, then I’m not sure what basis we should use for agreeing on community standards of ordinary niceness. One thought experiment I sometimes use for this purpose is: “How easy is it for me to imagine that a society twice as virtuous as present-day society would find [action] cartoonishly evil?”
I can imagine a more enlightened society responding to many of our mistakes with exasperation and disappointment, but I have a hard time imagining that they’d react with abject horror and disbelief to the discovery that consumers contributed in indirect ways to global warming — or failed to volunteer at soup kitchens. I have a much easier time imagining the “did human beings really do that?!” response to the enslavement and torture of of legions of non-human minds for the sake of modestly improving the quality of sandwiches.
I don’t want to be Thomas Jefferson. I don’t want to be “that guy who was totally kind and smart enough to do the right thing, but lacked the will to part ways with the norms of his time even when plenty of friends and arguments were successfully showing him the way.”
I’m not even sure I want to be the utilitarianThomas Jefferson, the counterfactual Jefferson who gives his money to the very best causes and believes that giving up his slaves would impact his wealth in a way that actually reduces the world’s expected utilitarian value.
I am something like a utiltiarian, so I have to accept the arguments of the hypothetical utilitarian slaveholder (and of Katja) in principle. But in practice I’m skeptical that an actual human being will achieve more utilitarian outcomes by reasoning in that fashion.
I’m especially skeptical that an 18th-century communityof effective altruists would have been spiritually undamaged by shrugging its shoulders at slaveholding members. Plausibly you don’t kick out all the slaveholders; but you do apply some social pressure to try to get them to change their ways. Because ditching ordinary niceness corrodes something important about individuals and about groups — even, perhaps, in contexts where “ordinary niceness” is extraordinary.
… I think. I don’t have a good general theory for when we should and shouldn’t adopt universal prohibitions against corrosive “utilitarian” acts. And in our case, there may be countervailing “ordinary niceness” heuristics: the norm of being inclusive to people with eating disorders and other medical conditions, the norm of letting altruists have private lives, etc.
Whatever the right theory looks like, I don’t think it will depend on our stereotypes of rationalist excellence. If it seems high-value to be a community of bizarrely kind people, even though “bizarre kindness” clashes with a lot of people’s assumptions about rationalists or about the life of the mind, even though the kindness in question is more culturally associated with Hindus and hippies than with futurists and analytic philosophers, then… just be bizarrely kind. Clash happens.
I might be talked out of this view. Paul raises the point that there are advantages to doubling down on our public image (and self-image) as unconventional altruists:
I would rather EA be associated with an unusual and cost-effective thing than a common and ineffective thing. The two are attractive to different audiences, but one audience seems more worth attracting.
On the other hand, I’d expect conventional kindness and non-specialization to improve a community’s ability to resist internal strife and external attacks. And plant people are common and unexceptional enough that eating fewer animals probably wouldn’t make vegetarianism or veganism one of our more salient characteristics in anyone’s eyes.
At the same time, plantpersonhood could help us do a nontrivial amount of extra object-level good for the world, if it doesn’t trade off against our other altruistic activities. And I think it could help us develop a stronger identity (both individually and communally) as people who are trying to become exemplars of morality and kindness in many different aspects of their life, not just in our careers or philanthropic decisions.
My biggest hesitation, returning to Katja’s calculations… is that there really is something odd about putting so much time and effort into getting effective altruists to do something suboptimal.
It’s an unresolved empirical question whether Chaos Altruism is actually a useful mindset, even for people to whom it comes naturally. Perhaps Order Altruism and the “just do the optimal thing, dammit” mindset is strictly better for everyone. Perhaps it yields larger successes, or fails more gracefully. Or perhaps rationalists naturally find systematicity and consistency more motivating; and perhaps the impact of meat-eating is too small to warrant a deontological prohibition.
More anecdotes and survey data would be very useful here!
[Epistemic status: I’m no longer confident of this post’s conclusion. I’ll say why in a follow-up post.]
We’re not very good at love yet. Some of the most textured and complex pleasures people experience happen in physically and emotionally intimate relationships — i.e., in the kinds of relationships that occasion some of our most spectacular tragedies and failures.
One reason we’re bad at love is that we lack a language, a culture, and an ingrained habit of honesty. The more we hide from others, the more we hide from ourselves. The more we hide from ourselves, the more confused and conflicted we become about our own wishes. And that in turn makes it harder to communicate in the future; and the cycle cycles on.
Why, then, are we so closed off to one another in the first place?
Lots of reasons. But one that strikes me as especially easy to fix is that we lack the vocabulary to express a lot of our desires and experiences. No words often means no awareness: no awareness of our current state, and no awareness of the alternative possibilities out there.
Selecting better terminology isn’t a hair-splitting exercise in intellectual masturbation, much as I adore intellectual masturbation. Done right, it’s a technology for enriching our emotional lives. Clear thinking can be an aid to deep feeling, and vice versa. If we want to be happier, want to make wiser decisions, we have to be able to talk about this stuff.
Below, I’ll list a few distinctions that I’ve found useful to explicitly mark in my own words and thoughts. I encourage you to play with them, test them, see which ones you like, and expand and improve on them all.
1. Love vs. amory
“Amory” is the name I use for being in a romantic or sexual relationship, and for all the little thoughts and deeds that make up those relationships. This idea is more specific than “love”, in some useful ways. It’s possible to love a platonic (or Platonic) friend, or a good sandwich, or oneself; but that’s not amory.
It’s also more inclusive than “love” in some useful ways. “But do you love your partner?” is a question I’ve seen people struggle with, because it mixes together questions about your present levels and varieties of affection, the social roles you see you relationship as fitting into, and your long-term feelings and relationship goals. Those might be important questions to answer, but it’s also nice to be able to just say that you interact with someone in physically or romantically intimate ways, without wading into those larger questions. And I find “it’s amory” less awkward and stilted than “it’s a romantic / sexual relationship.”
What do we call the people in an amorous relationship? “Partner” isn’t ideal, because it usually suggests a fairly serious relationship. And other terms (“boyfriend,” “lover,” “fuckpuppet,” “relata”…) are too gendered or otherwise specific.
My suggestion is to adopt the new term “amor“, borrowed from Latin for this targeted use. An amor is anyone you’re in a sexual or romantic relationship with. Where a “relationship” is a significant pattern of affinity and cooperation between some specific set of people. And a “romantic” relationship is one that’s characterized by communal acts, a presumption of very warm mutual feelings of caring, and behavior intended to produce mutual desire, pleasure, or intimacy associated with or analogous to sexual desire, pleasure, or intimacy. And a “sexual” relationship is one involving mutual arousal and willful stimulation of erogenous zones, especially…
… OK, that’s probably enough definition-mongering. But note that these are still vague definitions. Calling someone your “amor” (which sounds enough like the French amour that they’ll probably get the basic gist) doesn’t specify whether the relationship is sexual, romantic, physical, intellectual, serious, short-term, exclusive, primary, same-sex, with a boy, with a girl, with someone nonbinary, etc. It’s just… someone you have an existing non-platonic connection with. Self-labeling can be essentialist and restricting, but it doesn’t have to be.
Is this love? Are they my girlfriend? Am I straight? The rush to always have ready answers to questions about your identity, your desires, and the nature of your relationships is damaging because it assumes there’s always a clear answer to such questions; it assumes the answer can’t change on a regular basis; it punishes amors for disagreeing slightly on how to classify their relationship; and it discourages people from patiently waiting until they’ve gathered enough information about themselves to really know where they’re at. This is why the terms I recommend here are still pretty nebulous — but nebulous in specific, carefully chosen ways. Rather than giving up on the project of language and communication, or settling for what we have, we should try to make our language vague in the ways that mirror real human uncertainty and ambiguity, while getting rid of sources of obscurity that serve no good purpose.
2. Preference vs. behavior
Our language is terrible at distinguishing the things we want from the things we actually do. How many people are presently in their ideal relationship type? Most people’s amorous inner lives are greater than the sum of their relationships to date. And this is particularly important to recognize if we want to improve the fit between people’s preferences and their circumstances.
A useful example: Polyamory is a generic identity term, a giant tent-umbrella for people who prefer to have many concurrent romantic and sexual relationships, and for people actually engaged in such relationships. But we lack an easy way to distinguish those two subcategories, which is especially confusing when people’s preferences and relationship types change in different ways. I’ll call the first group of polyamors “polyphiles”, and the second group “multamors”. So:
Multamory is the act of being in a romantic and/or sexual relationship with more than one person over the same period of time. Multamory is opposed to unamory (a relationship with only one person) and anamory (being in no romantic and/or sexual relationships). Romantic anamory is being single. Sexual anamory is not having sex. Voluntary short-term sexual anamory is sexual abstinence (or continence); voluntary long-term sexual anamory is celibacy.
Polyphilia is a preference for having multiple simultaneous mid-to-long-term romantic and/or sexual partners. Polyphilia is opposed to monophilia (a preference for one partner) and aphilia (a preference for having no partners). We can distinguish romantic polyphilia from sexual polyphilia, and do the same for monophilia.
(… And I promise I’m not just promoting these terms because they avoid mixing Latin and Greek roots. I PROMISE.)
3. Preference vs. orientation
One’s orientation is the set of sex- and gender-related properties that one is romantically or sexually attracted to. “Attraction” here might mean sexual arousal, or intensely involving aesthetic appreciation, or a deep-seated desire to interact with persons who tend to belong to the category in question.
Such attraction comes in different levels and kinds of intensity (how attracted one is to a given range of individuals), scope (how large is the range of individuals the attraction applies to), context-dependency (how much the attraction varies with independent factors; how predictable it is given only the variables under consideration), and consistency (how much the attraction naturally or inevitably oscillates, including natural duration, how soon and how rapidly the attraction diminishes after its onset).
Preference is not orientation. My orientation is the universe of sensations (and interpretations of sensations) that viscerally entice and delight me, while my preference is what I actually want to have happen. I can be oriented toward (i.e., sensuously enjoy) chocolate ice cream, but choose not to indulge; or I can be oriented away from (i.e., dislike) chocolate ice cream, but choose to have some anyway — say, to win an ice-cream-eating contest.
Sexual orientation is what sex or gender one is sexually attracted to. Sexual attraction involves the kind of arousal we associate with sex, but it doesn’t need to involve a preference to actually have sex with the person one is attracted to. One can desire to fantasize about sex without wishing to go out and have the sex in question in the real world, for instance.
Romantic orientation is what sex or gender one is romantically attracted to. This is a much vaguer concept, encompassing the sorts of people one ‘crushes’ on, the sorts of people one enjoys dating and flirting with, the sorts of people one has especially emotionally intimate or intense friendships with, etc.
Orientation may be directed toward a primary sexual characteristic, or a secondary sexual characteristic, or any gendered physical or psychological characteristic. Gendering is partly culturally (and subculturally and individually) relative, and historically contingent, so there is no fixed set of universal characteristics that exhaust sexual or romantic orientation. What distinguishes ‘genders’ from other ways of categorizing people is just that they tend to be related in some (perhaps roundabout) fashion to the biological distinction between male and female.
Thus what will qualify as an ‘orientation’ from the perspective of one culture (e.g., a preference for people who wear long hair, dresses, and make-up) may instead qualify as a general kink in another. For some people, this will be a reason to collapse the whole idea of orientations, kinks, etc. into some larger categories, like ‘sexual turn-ons’ and ‘romantic turn-ons’.
4. Quantity
All the other confusions are amplified by the fact that our language is insensitive to quantitative difference. The Kinsey scale translates the heterosexual / homosexual dichotomy into a spectrum, which many people find useful. But it’s not clear what the scale is quantifying, which sucks a lot of the value out of it. For instance, it doesn’t distinguish weak but constant desire from intense but intermittent desire; nor does it clearly distinguish behavior, preference, and orientation.
I mentioned above that vagueness can be more useful than precision when you’re uncertain, or when there are risks associated with communicating too much too fast. Equally, we should have the ability to be precise when it is useful to clearly and concisely define ourselves to others. Language should be vague, and non-vague, in exactly the ways that people are most likely to need.
Returning to the example of polyamory, a scale that acknowledges degrees of personal preference might look like:
Strong Polyphile: Only willing to be in relationships that involve, or seek to involve, three or more people.
Moderate Polyphile: Significantly prefers multamorous relationships, but open to unamorous relationships too, possibly even ‘closed’ ones.
Weak Polyphile: Open to multamory or unamory, but slightly prefers multamory.
Ambiphile: Equally open to multamory or unamory, with no preference for either.
Weak Monophile: Open to either, but slightly prefers unamory.
Moderate Monophile: Significantly prefers unamory, but open to ‘open’ or polyamorous relationships.
Strong Monophile: Only willing to be in two-person relationships.
There are lots of other variables of human experience and behavior that would be quite easy to sum up in a few words: your relationship status at different times (e.g., ‘I’m a past-multamor’ or ‘I’m a recent-multamor’ vs. ‘I’m a present-multamor’), exactly how many people you’re in a relationship with (biamory, triamory…) or would like to be in a relationship with (diphilia, triphilia…), where you fall on various spectra from sexual to asexual or romantic to aromantic, how curious you are about a certain behavior or relationship type, how much masculinity or femininity (of various kinds) you prefer in your partners, etc.
We could carve up these concepts more finely, but I find that these distinctions are the ones I end up needing the most often. If we were categorizing food tastes rather than relationship tastes, we’d say that an ice cream orientation amounts to craving and/or enjoying the taste of ice cream, an ice cream preference amounts to an all-things-considered desire to eat ice cream when given a chance, and ice cream amory is a diet of routinely eating ice cream.
But since ice cream isn’t the psychosocial clusterfuck that interpersonal affection is, and since there’s less at stake if you fail to clearly communicate or understand your mental states about ice cream, I’d expect that there’s more discursive low-hanging love fruit than low-hanging ice cream fruit out there.
In a December 14 comment on his blog, Scott Aaronson confessed that the idea that he gains privilege from being a man feels ‘alien to his lived experience’. Generalizing from his own story, Aaronson suggested that it makes more sense to think of shy nerdy males as a disprivileged group than as a privileged one, because such men are unusually likely to be socially isolated and stigmatized, and to suffer from mental health problems.
Here’s the thing: I spent my formative years—basically, from the age of 12 until my mid-20s—feeling not “entitled,” not “privileged,” but terrified. I was terrified that one of my female classmates would somehow find out that I sexually desired her, and that the instant she did, I would be scorned, laughed at, called a creep and a weirdo, maybe even expelled from school or sent to prison. You can call that my personal psychological problem if you want, but it was strongly reinforced by everything I picked up from my environment: to take one example, the sexual-assault prevention workshops we had to attend regularly as undergrads, with their endless lists of all the forms of human interaction that “might be” sexual harassment or assault, and their refusal, ever, to specify anything that definitely wouldn’t be sexual harassment or assault. I left each of those workshops with enough fresh paranoia and self-hatred to last me through another year. […]
Of course, I was smart enough to realize that maybe this was silly, maybe I was overanalyzing things. So I scoured the feminist literature for any statement to the effect that my fears were as silly as I hoped they were. But I didn’t find any. On the contrary: I found reams of text about how even the most ordinary male/female interactions are filled with “microaggressions,” and how even the most “enlightened” males—especially the most “enlightened” males, in fact—are filled with hidden entitlement and privilege and a propensity to sexual violence that could burst forth at any moment.
Because of my fears—my fears of being “outed” as a nerdy heterosexual male, and therefore as a potential creep or sex criminal—I had constant suicidal thoughts. As Bertrand Russell wrote of his own adolescence: “I was put off from suicide only by the desire to learn more mathematics.” At one point, I actually begged a psychiatrist to prescribe drugs that would chemically castrate me (I had researched which ones), because a life of mathematical asceticism was the only future that I could imagine for myself.
The two main responses have been Laurie Penny’s “On nerd entitlement” and Amanda Marcotte’s “MIT professor explains: The real oppression is having to learn to talk to people.” These led to a rejoinder from Scott Alexander (“Untitled“) and a follow-up by Aaronson (“What I believe“). My impression is that each response in this chain has at least partly misunderstood the preceding arguments, but I’ll do my best to summarize the state of the debate without making the same mistake, borrowing liberally from others’ comments.
1. Does feminist rhetoric bear some of the blame?
Nick Tarleton responds to Scott Aaronson’s anecdote:
Scott attributes his problems entirely(?) to feminism. I’ve had similar (milder) bad experiences, but it’s really not clear to me in retrospect how much to attribute them to gender/sex-specific cultural stuff rather than general social anxiety and fear of imposing. Within gender/sex-specific cultural stuff, it’s really not clear how much to attribute to feminism rather than not-really-feminist (patriarchal, or Victorian reversed-stupidity-patriarchal) background ideas about male sexuality being aggressive, women not wanting sex, women needing protection, and the like. (Which feminism has a complicated relationship with — most feminists would disavow those ideas, but in my experience a lot of feminist rhetoric still trades on them, out of convenience or just because they’re embedded in the ways we have of thinking and talking about gender issues and better ways haven’t propagated.)
And Alexander writes:
Laurie Penny has an easy answer to any claims that any of this is feminists’ fault: “Feminism, however, is not to blame for making life hell for ‘shy, nerdy men’. Patriarchy is to blame for that.”
I say: why can’t it be both? […]
Pick any attempt to shame people into conforming with gender roles, and you’ll find self-identified feminists leading the way. Transgender people? Feminists led the effort to stigmatize them and often still do. Discrimination against sex workers? Led by feminists. Against kinky people? Feminists again. People who have too much sex, or the wrong kind of sex? Feminists are among the jeering crowd, telling them they’re self-objectifying or reinforcing the patriarchy or whatever else they want to say. Male victims of domestic violence? It’s feminists fighting against acknowledging and helping them.
Yes, many feminists have been on both sides of these issues, and there have been good feminists tirelessly working against the bad feminists. Indeed, right now there are feminists who are telling the other feminists to lay off the nerd-shaming. My girlfriend is one of them. But that’s kind of my point. There are feminists on both sides of a lot of issues, including the important ones.
Alexander is right that “Whether or not a form of cruelty is decreed to be patriarchy doesn’t tell us how many feminists are among the people twisting the knife.”, and he’s right that people who accuse nerds of misogyny often appeal in the same breath to ableist, classist, lookist, fat-shaming, and heteronormative (!) language. Being a feminist doesn’t mean you can never be cruel to people, or never misrepresent them. Consider the way Marcotte elects to summarize Aaronson’s disclosure of his many-year struggle with mental illness:
Translation: Unwilling to actually do the work required to address my social anxiety—much less actually improve my game—I decided that it would be easier to indulge a conspiracy theory where all the women in the world, led by evil feminists, are teaching each other not to fuck me. Because bitches, yo.
Marcotte adds, “I’m not a doctor, but I can imagine that it’s nearly impossible to help someone who is more interested in blaming his testicles, feminism, women generally, or the world for his mental health problems than to actually settle down and get to work at getting better.” Or, as Ozy Frantz of Thing of Thing puts it: “how dare those mentally ill people go about having distorted and inaccurate thoughts”.
Penny’s piece too ignores the possibility that feminist discourse norms are causing any harm. Sarah Constantin of Otium responds in a Facebook comment:
So, there are women nerds who make feminism their identity. The author [Penny] is one of them. And I think you do that if nerd culture treats you badly and feminist culture treats you well. But feminist culture doesn’t treat everyone well. Sometimes it’s *full* of anti-nerd contempt.
I’m unusual in this respect, but I’m much more offended and bothered by people who don’t like how my brain works than by people who don’t like what’s between my legs. I’m more wary of feminists who I suspect of wanting to mock my personal quirks and hobble my professional success than I am of sexism in STEM. I see comments on anti-SV articles like “this is what happens when you give autistic people money and power” and I get mad. I take it personally. A lot more personally than I take insults to women. Maybe it’s not fair of me, but that’s how my emotional calculus stacks up.
Scott Aaronson is right that there is a particular kind of damage that is inflicted ONLY on men and boys [eta: and queer women/girls] who want to do right by women and do not want to be “creeps”.
In general, there is a kind of damage that is inflicted ONLY upon the morally scrupulous. If you really want to be good, the demands of altruistic or self-sacrificing goodness can be paralyzing. The extreme case of this is scrupulosity as a symptom of OCD. This is a kind of pain that simply does not affect people whose personal standards are more relaxed. […]
What actually happens is that a highly scrupulous person reads a bunch of things that seem to put moral obligations on him, with the implication that the correct amount of moral obligation is always “more,” and *never* finds any piece of feminist writing that explicitly says “this is enough, you can stop here” because there aren’t that many people period who understand that obsessive moral paralysis is a problem. And so you get Scott Aaronson and many others like him (including some women!)
What we need is people talking about the problem of obsessive moral paralysis. “Yes, you *do* have some moral obligations, but they are finite and attainable. Here are realistic examples of people acting acceptably. Here are real-world examples of good men. You can be good without being a martyr.”
There is a lot to like about this piece. Penny correctly points out that women have an extra layer of marginalization on top of what Aaronson went through, and that Aaronson didn’t account for that in his comment.
However, I think the thing that rubbed me wrong about Penny’s piece is that she didn’t offer any account of the role that feminism played in Aaronson’s tortured adolescence, which is an experience unique to the privileged, and which Penny didn’t acknowledge at all. […]
Penny claims the mantle of feminism, yet she refuses to acknowledge the role that her movement played in Aaronson’s tragic story. She demands that Aaronson, as a nerdy white man, be “held to account” for the lack of women in STEM, yet refuses his call that feminism be held to account for its at-worst abusive and at-best unkind rhetoric toward people deemed “privileged.”
The thesis of Penny’s piece is that as a nerdy woman, she went through all of the hell that Aaronson did, plus extra because she’s a woman. I think if she wanted to make that claim, she should have some kind of argument that Aaronson’s unique pain somehow doesn’t count or is somehow lesser than the pain of being a woman. I don’t find that obvious, and I don’t think she even attempted to make a case for it.
I think, as feminist advocates, we are obligated to recognize the darker side of our community and its potential to cause real-world harm. Aaronson’s piece was a real, raw testimonial documenting some of that harm. Penny’s piece just seemed like she was trying to handwave it away. She was compassionate, but she ultimately didn’t seem like she was listening.
I tend to recognize this because it’s a problem I have often — when someone tells me about an issue they have, I try to relate it to my own experience. On the one hand, a measure of that is how empathy/sympathy works. But on the other hand, I have a tendency to ignore the differences that make the other person’s pain and loss unique. I feel like that may be what’s going on here.
Chana Messinger raises the possibility that the harm inflicted on some scrupulous people could be “an unfortunate but necessary side effect of spreading the right messages to everyone else”. To know whether that’s so, we’ll need to investigate how common a problem this is, and whether there are easy ways to avoid it. At this stage, however, relatively few people have acknowledged that this is a concern. I certainly wasn’t aware of it until recently, and I’m now having to rethink how I talk about moral issues.
I know there are a couple different definitions of what exactly structural oppression is, but however you define it, I feel like people who are at much higher risk of being bullied throughout school, are portrayed by the media as disgusting and ridiculous, have a much higher risk of mental disorders, and are constantly told by mainstream society that they’re ugly and defective kind of counts. If nerdiness is defined as intelligence plus poor social skills, then it is at least as heritable as other things people are willing to count as structural oppression like homosexuality (heritability of social skills, heritability of IQ, heritability of homosexuality)[.]
The three main objections I’ve heard to this line of reasoning are that (1) the shaming and bullying nerds experience is relatively minor, (2) nerds are privileged, and (3) anti-nerd sentiment is really some combination of lookism, ableism, etc.
3 strikes me as a reasonable (though not conclusively demonstrated) position, and is still consistent with points like Frantz’s:
it is amazing how laurie penny can write this entire article without mentioning that neurodiversity is a form of oppression????
“Privilege doesn’t mean you don’t suffer, which, I know, totally blows.” except that a lot of shy nerdy men are suffering because… they lack privilege… on at least one axis
Intersectionality also suggests that anti-nerd sentiment won’t perfectly reduce to its constituent parts. ‘Nerd’ could be a composite like ‘Chinese-American lesbian’ or ‘poor transgender Muslim’, but third-wave feminist theory denies that the social significance of ‘poor transgender Muslim’ is just a conjunction of the significance of ‘poor person’, ‘transgender person’, and ‘Muslim’.
Alexander gives a good response to 2, pointing out that being Jewish (for example) can simultaneously result in being privileged and oppressed. 1 seems like an open empirical question, provided we can agree on a threshold level of harm that is required for something to qualify as ‘oppression’, ‘discrimination’, etc.
Alternatively, one might object that the ‘structures’ Alexander points to are cognitive and cultural, but not institutional. Perhaps there isn’t enough economic, legal, and political restriction on nerds for them to qualify as ‘oppressed’ in the relevant sense. (And perhaps the same is true of Jews in 21st-century America, and we should think of Jews in that context as ‘historically oppressed’ but not actively oppressed? One man’s modus ponens is another’s modus tollens.)
Of course, it could turn out that ‘shy nerds’ suffer as a group from a distinct flavor of oppression even if ‘shy male nerds’ don’t. And Messinger adds in correspondence: “However strong or weak the case for nerd oppression, the case for nerd oppression by feminists is an order of magnitude or two weaker.”
But ‘oppressed’ is in the end just a word. What’s the substantive question under debate?
If some categories of suffering are unusually intense, widespread, and preventable, it makes sense to adopt the heuristic ‘allocate more attention and sympathy to those categories’. This is the schematic reasoning behind treating triggers as qualitatively more important than aversions, or treating racism as qualitatively more important than run-of-the-mill bullying. (At least, it’s the good reasoning. There may be worse reasons on hand, such as medical essentialism and outgroup antipathy.)
However, these heuristics require some policing, or they’ll degrade in effectiveness. Once everyone agrees that ‘triggers’ demand respect, people without PTSD symptoms have an incentive to expand the ‘trigger’ concept to fit their most intense preferences. Once everyone agrees that ‘oppressed groups’ get special consideration, disadvantaged people outside conventional axes of oppression have an incentive to expand the idea of ‘oppression’. This is inevitable, even if no one is being evil. Thus we need to take into account the upkeep cost of preserving these categories’ meanings when we decide whether they’re useful.
Many people intuit that we should have different norms in Europe and the Anglophone world about when it’s OK to belittle white people as a group, versus when it’s OK to belittle black people. The former is “punching up,” the latter “punching down.” Without a clear sense of whether geeks are ‘above’ or ‘below’ us, this heuristic short-circuits here; so the practical import of this debate is how strongly we should endorse a norm ‘don’t pick on shy geeky men as a group’.
Even if geeks aren’t oppressed and their problems are much smaller than those of women, black people, LGBT people, etc., their suffering is still real, and there are probably good ways to reduce it. I don’t know what the best solution here is, but trigger warnings and carefully-labeled safe spaces may be useful for people who want to avoid discussing various forms of feminism. For public spaces, perhaps we need a new concept of ‘punching straight ahead’, and new norms for when that’s OK. I generally prefer to err on the side of niceness, but I understand the arguments for being a loud gadfly, and I don’t know of a practical way to keep memes of wrath from outcompeting pacific memes.
Alexander, however, worries that even raising the issue of punching up vs. down is a red herring. He accuses feminists of misrepresenting Scott Aaronson’s ‘my suffering is real and matters’ as ‘my suffering is the most real and most important kind of suffering’:
If you look through Marcotte’s work, you find this same phrasing quite often. “Some antifeminist guy is ranting at me about how men are the ones who are really oppressed because of the draft” (source). […] But Aaronson is admitting about a hundred times that he recognizes the importance of the ways women are oppressed. The “is really oppressed” isn’t taken from him, it’s assumed by Marcotte. Her obvious worldview is – since privilege and oppression are a completely one dimensional axis, for Aaronson to claim that there is anything whatsoever that has ever been bad for men must be interpreted as a claim that they are the ones who are really oppressed and therefore women are not the ones who are really oppressed and therefore nothing whatsoever has ever been bad for women.
Alexander blames this on “Insane Moon Logic”. I find it likelier that different people, Alexander included, are just focusing on different aspects of Aaronson’s comment, to fit them into different narratives. Aaronson doesn’t deny that women are disadvantaged in various ways, but he, not Marcotte or Penny, is the person who raised the issue of whether geeks are more disprivileged than women. It shouldn’t surprise us that some eyebrows would be raised at lines like:
[1] Alas, as much as I try to understand other people’s perspectives, the first reference to my ‘male privilege’—my privilege!—is approximately where I get off the train, because it’s so alien to my actual lived experience.
[2] But I suspect the thought that being a nerdy male might not make me “privileged”—that it might even have put me into one of society’s least privileged classes—is completely alien to your way of seeing things.
[3] My recurring fantasy, through this period, was to have been born a woman, or a gay man, or best of all, completely asexual, so that I could simply devote my life to math, like my hero Paul Erdös did. Anything, really, other than the curse of having been born a heterosexual male, which for me, meant being consumed by desires that one couldn’t act on or even admit without running the risk of becoming an objectifier or a stalker or a harasser or some other creature of the darkness.
[4] As I see it, whenever these nerdy males pull themselves out of the ditch the world has tossed them into, while still maintaining enlightened liberal beliefs, including in the inviolable rights of every woman and man, they don’t deserve blame for whatever feminist shortcomings they might still have. They deserve medals at the White House.
1 appears to deny the existence of male privilege; 2 suggests that nerdy men may be “one of society’s least privileged classes”; 3 calls being a heterosexual man a “curse”; and 4 can easily be read as demanding cookies (“medals”, even) for insecure men who don’t actively reject women’s rights, no matter how glaring their “feminist shortcomings”.
Aaronson has since explained that he does believe in male privilege, and he has walked back claim 2 to just “the problem of the nerdy ‘heterosexual male’ is surely one of the worst social problems today that you can’t even acknowledge as being a problem” (emphasis added). Still, a feminist could reasonably worry that Aaronson is vacillating between a motte (‘nerds suffer too!’ or ‘there exists at least one person who was harmed by feminist rhetoric!’) and a bailey (‘nerds have it worse than all or most other groups’, or ‘pointing out problems with nerd culture is immoral’).
I hate the ‘motte’/’bailey’ framing — it encourages people to assume malice, even when we should be looking into the possibility that our conversation partner has made a mistake, or has updated their beliefs, or consists of multiple dissenting factions. But if you’re going to use the motte/bailey idea to accuse your enemies of deceit (or Moon Logic), be sure you spend at least as much time testing how readily it applies to your own side.
I don’t know whether Aaronson stands by his younger self’s belief that he would have been better off as a non-white non-heterosexual non-male. As Tarn Somervell Fletcher notes:
I’ve seen plenty of responses that seemed to have completely taken on board everything he’s [Aaronson’s] said, and just think that he’s misjudged how bad it is for some people. When you’re comparing two people’s oppression, or suffering etc. (which is a terrible terribly unproductive idea but everyone seems determined to do it anyway), the default is that both people are going to discount (or, fail to count?) the others’ experience.
I agree with Aaronson’s statement, “This whole affair makes me despair of the power of language to convey human reality” (only I came in pre-despairing). Since people are extremely bad at simulating others’ life experiences, Aaronson is likely to misunderstand how bad women, black people, trans people, etc. have it. (This is of course consistent with acknowledging the psychological importance of Aaronson’s feeling that he had it worse than everyone else.) For the same reason, a black lesbian social butterfly would be likely to misunderstand how bad Aaronson has it. If we only rely on who has the most eloquent anecdotes, rather than on reliable population-wide quality-of-life measures, we aren’t going to get very far with these discussions.
And perhaps it isn’t worth the effort, if it’s possible for us to come up with norms of discourse that work OK even when we don’t all start with perfectly accurate beliefs about people’s demographics and relative levels of privilege. Even if punching up is justifiable in principle, we may not want to come in swinging when there’s a chance we’re misappraising the situation.
What can you do that would have the best chance of making the world a better place? As Scott Siskind puts the question:
Most donors say they want to “help people”. If that’s true, they should try to distribute their resources to help people as much as possible. Most people don’t.
In the “Buy A Brushstroke” campaign, eleven thousand British donors gave a total of £550,000 to keep the famous painting “Blue Rigi” in a UK museum. If they had given that £550,000 to buy better sanitation systems in African villages instead, the latest statistics suggest it would have saved the lives of about one thousand two hundred people from disease. Each individual $50 donation could have given a year of normal life back to a Third Worlder afflicted with a disabling condition like blindness or limb deformity.
Most of those 11,000 donors genuinely wanted to help people by preserving access to the original canvas of a beautiful painting. And most of those 11,000 donors, if you asked, would say that a thousand people’s lives are more important than a beautiful painting, original or no. But these people didn’t have the proper mental habits to realize that was the choice before them, and so a beautiful painting remains in a British museum and somewhere in the Third World a thousand people are dead. […]
It is important to be rational about charity for the same reason it is important to be rational about Arctic exploration: it requires the same awareness of opportunity costs and the same hard-headed commitment to investigating efficient use of resources, and it may well be a matter of life and death.
Holden Karnofsky of GiveWell notes (in this video) that it isn’t easy to spot an ineffective charity. Many popular charities are “not even failing to do good, but doing harm”. At the same time, the positive difference you can make with a carefully targeted, empirically vetted charitable donation is extraordinary. Philosopher William MacAskill voices his excitement:
Imagine you’re walking down the street and see a building on fire. You run in, kick the door down—smoke billowing—you run in and save a young child. That would be a pretty amazing day in your life: That’s a day that would stay with you forever. Who wouldn’t want to have that experience? But the most effective charities can save a life for $4,000, so many of us are lucky enough that we can save a life every year through our donations. When you’re able to achieve so much at such low cost to yourself…why wouldn’t you do that? The only reason not to is that you’re stuck in the status quo, where giving away so much of your income seems a little bit odd.
GiveWell is the top organization investigating the impact charities have upon the most disadvantaged people in the world. If you want to be confident you’re really improving the world in a concrete way, really saving lives, it’s hard to do better than following GiveWell’s new annual giving recommendations (updated December 2014). The new recommendations are that each $100 you give to charity over the next 4 months break down as follows:
(The $10 to GiveWell is an operating expenses donation GiveWell is requesting separately. I’m including it in the breakdown on the assumption that if you trust GiveWell’s expertise enough to base your decisions on their research, you probably also want to support GiveWell’s ability to keep those recommendations up to date.)
The above breakdown is intended to minimize the risk that, say, AMF keeps getting swamped with donations long after it’s reached its yearly target, while donors neglect DtWI. GiveWell’s goal is that AMF receive $5 million from individual donors over the next 4 months; GiveDirectly between $1 million and $25 million; SCI $1 million; and DtWI between $500,000 and $1 million. If everyone donates in the above proportion, then every top-effectiveness charity will be equally likely to hit its minimum target.
If you want to follow this breakdown exactly, go to https://givewell.secure.nonprofitsoapbox.com/donate-to-givewelland select “Grants to recommended charities (90%) and unrestricted (10)%” under “How should we use your gift?”. If you’d rather just donate to one organization and not split it up in this way, GiveWell suggests giving to the Against Malaria Foundation; you can do so by setting “How should we use your gift?” to “Grants to recommended charities” and writing under Comments “all to AMF”.
Edit 12/31: More specifically, Elie Hassenfeld of GiveWell writes:
For donors who have a high degree of trust in and alignment with GiveWell, we recommend unrestricted gifts to GiveWell. For donors who want to support our work because they value it but are otherwise primarily interested in supporting charities based on neutral recommendations, strong evidence, etc., we recommend giving 10% of their donation to GiveWell.
What do these charities do?
GiveWell staff make a site visit to a charitable organization in western India.
AMF, GiveDirectly, SCI, and DtWI all focus on combating poverty and disease in poor regions of Africa and Asia. This isn’t an arbitrary choice; your dollar can go orders of magnitude farther in the developing world than in developed nations. Dylan Matthews of Voxwrites:
GiveWell actually looked into a number of US charities, like the Nurse-Family Partnership program for infants, the KIPP chain of charter schools, and the HOPE job-training program. It found that all were highly effective, but far more cost intensive than the best foreign charities. KIPP and the Nurse-Family Partnership cost over $10,000 per child served, while deworming programs like SCI’s and Deworm the World’s generally cost about $0.50 per child treated.
AMF distributes insecticide-treated bed nets in the Democratic Republic of the Congo and other countries. This prevents transmission of malaria by mosquito bite, reducing child mortality and anemia and improving developmental outcomes. (General information on insecticide-treated nets.)
GiveDirectly makes secure cash payments to poor households they’ve vetted in Kenya and Uganda. Recipients may then use this money however they wish. This generally results in improved food security and investments with high rates of return. Direct cash transfers are a good way to avoid the common mistake of trying to micromanage the lives of people in the developing world. Impoverished individuals usually have much more robust and fine-grained knowledge of their own needs than any philanthropic organization or donor does, and they have clearer incentives to make sure every penny gets used wisely. (General information on cash transfers.)
SCI works with governments in sub-Saharan Africa to distribute deworming pills to schoolchildren, improving nutrition and developmental outcomes. DtWI does similar deworming work in India, Kenya, and Vietnam, with more focus on improving existing programs than on creating and scaling up programs. (General information on deworming.)
How do these charities compare to each other?
GiveWell publishes its evidence and reasoning process publicly so others can examine it in as much detail as they’d like and identify points of disagreement. That gives you a chance to deviate from GiveWell’s recommendations in an informed way, if you disagree with GiveWell about the tradeoffs involved. To summarize GiveWell’s take:
Cost-effectiveness: GiveDirectly is probably the least cost-effective, in spite of transferring 87 to 90 cents per dollar donated directly into the hands of poor individuals. This is because it still appears to be cheaper to cure the worst widespread diseases than to directly alleviate the poverty of otherwise healthy people. AMF and SCI are maybe 5-10 times as effective as GiveDirectly, and DtWI may be twice as effective as SCI.
Strength of supporting evidence: We can be relatively confident GiveDirectly is having the impact it intends to. The case for AMF is weaker, and the case for SCI is weaker still. DtWI has the weakest case, because its political focus places it more causal steps away from its goal. On the other hand, DtWI’s transparency and self-monitoring is much better than SCI’s, so there’s more likelihood we’ll notice in the future if DtWI has gone wrong than if SCI has.
History of rolling out more program: GiveDirectly and SCI have a strong track record. AMF and DtWI have an adequate track record.
Room for more funding: GiveDirectly is scaling up amazingly well, and could continue to make use of tens of millions more dollars this year. AMF has had difficulty finding enough places to distribute bed nets to use its funds effectively; however, it now appears to have fixed that problem and has a lot more room for funding it can use to leverage more distribution deals. DtWI and SCI have relatively little room for funding.
In their personal charitable donations, GiveWell staff generally followed the above recommendations, though several staffers gave substantially more to GiveDirectly (to reward its transparency and self-monitoring, and to be sure of having a positive impact), and less to the deworming charities. Other people who have explained how they’re factoring in GiveWell’s new recommendations include philosopher Richard Chappell, blogger Unit of Caring, consultant Chris Smith, and economist Robert Wiblin.
What are other contenders for the best causes out there?
If you’re interested in credible but less thoroughly vetted efforts to combat global poverty, you may want to look at GiveWell’s second tier of promising charities:
Development Media International, an organization that broadcasts health information to people in the developing world on television and radio.
Living Goods, an organization that “[sells] health and household goods door-to-door in Uganda and Kenya and [provides] basic health counseling. They sell products such as treatments for malaria and diarrhea, fortified foods, water filters, bed nets, clean cook stoves and solar lights.”
Following GiveWell’s recommendations is probably the best way to measurably improve the lives of human beings who are suffering and dying today. However, the same evidence-based approach should allow us to identify relatively effective and ineffective causes in the developed world too. GiveWell is in the early stages of looking for the most urgent and tractable projects in U.S. policy, and one of their top contenders is prison reform. If you live in the U.S. and are more interested in local issues, you may want to follow the work of:
Open Philanthropy Project, a spin-off of GiveWell that looks into general causes that may be unusually important, as opposed to specific charities that are unusually well-targeted and efficient. One of their focus areas is policy-oriented philanthropy.
On the other hand, there are some local, activism-oriented charities that may have a much larger impact than any I’ve listed so far — charities focused on non-human animal welfare. If you aren’t just worried about human suffering, you may want to give to:
The Humane League, a top-notch animal welfare nonprofit that discourages factory farming through outreach and advertising. They attempt to test the efficacy of their methods at Humane League Labs.
Another excellent way to try to outdo GiveWell’s recommended charities is to help fund scientific research into the life-saving innovations of the future. Historically, scientific and technological progress has had a vastly larger effect on human welfare than any philanthropy has, and this is another major area the Open Philanthropy Project hopes to investigate in the future. For now, the main scientific institute I can recommend donating to is:
The Future of Humanity Institute, an Oxford-based research center that investigates social and technological changes that may impact our future as a species, as well as the effects of systematic uncertainty and bias on our attempts to predict such developments.
If there are interesting developments over the next year, I’ll update this advice December 2015. For now, the main organizations I recommend giving to are GiveWell and its top charities (donation page), the Humane League (donation page), or the Future of Humanity Institute (donation page), in increasing order of ‘uncertainty about the organization’s real effects’ and ‘probability of having a large positive impact’.
Edit 12/28: GiveWell has updated their donation page to include a “Grants to recommended charities (90%) and unrestricted (10)%” option. I’ve modified my above advice to make use of that new option. I’ve also started a birthday fundraiser to give to the charities I covered above.
The reason why people on tumblr over-use the concept of “trigger” rather than just “thing I don’t like” or “thing that makes me angry” or “thing that makes me sad” is that, literally, in the political/fandom part of tumblr culture are required to establish your right not to read a thing, and you only have rights if you can establish that you’re on the bad end of an axis of oppression. Hence, co-opting the language of mental illness: trigger.
i.e. trigger warning culture is a rational response to an environment in which media consumption is mandatory. It’s not hypersensitivity so much as the only way to function.
There is a secondary thing, which is, here we are all oppressed, which ties into the feeling that you only have rights if you can establish that you’re at the bad end of an axis of oppression, but I’m not sure I can totally articulate that thing.
The idea that oppression confers legitimacy does seem to be ascendant, and not just on tumblr. Hostile political debates these days often turn into arguments about which side is the injured party, with both claiming to be unfairly caricatured or oppressed. This is pretty bad if it displaces a substantive exchange of ideas, though it may be hard to fix in a society that’s correcting for bias against oppressed groups. The cure isn’t necessarily worse than the disease, though that’s a question worth looking into, as is the question of whether people can learn to see through false claims of grievance.
On the other hand, I don’t think ‘I will (mostly) disregard your non-triggering aversions’ implies ‘you only have rights to the extent you’re oppressed’. I think the deeper problem is that social interaction between strangers and acquaintances is increasingly taking place in massive common spaces, on public websites.
If we’re trapped in the same common space (e.g., because we have a lot of overlapping interests or friends), an increase in your right to freely say what you want to say inevitably means a decrease in my right to avoid hearing things I don’t want to hear. Increasing my right to only hear what I want to will likewise decrease your right to speak freely; at the very least, you’ll need to add content warnings to the things you write, which puts an increasing workload on writers’ plates as the list of reader aversions they need to keep track of grows longer. (Blogging and social media platforms also make things much more difficult, by forcing trigger warnings and content to compete for space at the start of posts.)
I don’t know of any easy, principled way to solve this problem. Readers can download software that blocks or highlights posts/websites using specific words, such as Tumblr Savior and FB Purity. Writers can adopt content warnings for the most common and most harmful trigger and aversions out there, or the ones that are too vague to be caught by word/phrase blockers.
But vague rules are hard to follow. So it’s understandable that people would gravitate toward a black-and-white ‘trigger’ v. ‘non-trigger’ dichotomy in the hope that the scientific authority and naturalness of a medical category would simplify the problem of deciding when the reader’s right-to-not-hear outweighs the writer’s right-to-speak-freely. And it’s equally understandable that people who don’t have ‘triggers’ in the strictest sense, but are still being harmed in a big way by certain things people say (or ways people say them), will want to piggyback off that heuristic once it exists.
‘Only include content warnings for triggers’ doesn’t work, because ‘trigger’ isn’t a natural kind and people mean different things by it. Give some groups an incentive to broaden the term and others an incentive to narrow it, and language will diverge even more. ‘I’ll only factor medical information into my decisions about how to be nice to people’ is rarely the right approach.
‘Always include content warnings for triggers’ doesn’t work either. There are simply too many things people are triggered by.
If we want rules that are easy to follow in extreme cases while remaining context-sensitive in mild cases, we’ll probably need some combination of
‘Here are the canonical content warnings that everyone should use in public spaces: [A], [B], [C]…’
and
‘If you have specific reason to think other information will harm part of your audience, the nice thing to do is to have a private conversation with some of those audience members and consider adding more content warnings. If it’s causing a lot of harm to a lot of your audience, adding content warnings transitions from “morally praiseworthy” to “morally obligatory”.’
The ambiguity and context-sensitivity of the second rule is made up for by the very clear and easy-to-follow first rule. Of course, I only provided a schema. The whole point of the first rule is to actually give concrete advice (especially for cases where you don’t know much about your audience). That project requires, if you’re going to do it right, that we collect base rate information on different aversions and triggers, find a not-terrible way of ranking them by ‘suffering caused’, and find a consensus threshold for ‘how much suffering it’s OK for a random content generator to cause in public spaces’.
That wouldn’t obviate the need for safe spaces where the content is more carefully controlled, but it would hopefully make movies, books, social media, etc. safe and enjoyable for nearly everyone, without requiring people to just stop talking about painful topics.
Impulse buying is a thing. We have ready-made clichés for picking it out. Analogously, ‘impulse giving’ is a thing, where you’re spontaneously moved by compassion to help someone out without any advance planning. The problem with most impulse giving is that it gives you the same warm glow and sense of moral license as high-impact giving, without making as much of a difference. Peter Singer puts it best:
My experience with the effective altruism community is that they don’t do much to encourage impulse giving of any kind. If you can give to low-impact charities in the heat of the moment, you should be able to do the same for high-impact charities; yet I think of ‘giving effectively’ as affectively cold, carefully budgeted.
This is probably mostly a good thing. We want people to think carefully about their big decisions, if it improves decision quality. However, the stereotype has its disadvantages. If people think they need to go through a long process of deliberation before they can give, they can end up procrastinating indefinitely. Borrowing Haidt’s analogy, we’re discouraging the elephant (our system-1 emotions and intuitions) from getting passionate and worked up about the most important things we do, while encouraging the elephant’s rider (our system-2 reasoning and deliberation) to overanalyze and agonize over decisions.
Effective altruism as it exists today is aligned with the legions and principalities of Order. I’d bet we can change that in some respects, if we so wish, without giving up our allegiance to Goodness.
Affective altruism
Eliezer Yudkowsky suggests that we “purchase fuzzies and utilons separately“. Better to spend some of your time on feel-good do-gooding and some on optimal high-impact do-gooding, rather than pursuing them simultaneously and doing a terrible job at both. In “Harry Potter and the Fuzzies of Altruism“, I noted that there are different kinds of fuzzies people can get for doing good.
One of these varieties is particularly valuable, because it doesn’t need to be purchased separately. I speak of the slytherfuzzy, that warm glow you get from being especially efficient and effective. Do-gooders who find cool, calculated pragmatism strongly motivating in its own right have an obvious leg up. I myself am more motivated by narrative, novelty, and love-of-neighbor than by Winning, but I’d love to find a way to steal that trick and bind my own reward center more tightly to humanitarian accomplishment.
If you’re trying to make yourself (or others) more enthusiastic about purchasing utilons, it may be helpful to make the way you buy utilons as fuzzy-producing as possible. This needn’t dilute the outcome. Select a charity based on a sober cost-benefit analysis, but give chaotically, if chaos happens to gel with your psychology. Impulse giving and effective altruism don’t have to be placed in separate mental boxes forever; we can invent new categories of behavior that wed Chaos Altruism’s giddy spontaneity to Order Altruism’s focus and rigor.
I’d expect mixed approaches to work best. E.g., you can settle on a fixed percentage of your income to give to a high-impact cause every year, but build a habit of giving bonus donations to that cause when the mood strikes you. I’m a big fan of using specific benevolence triggers. For example: ‘When someone on the street asks me for money, and I feel an urge to give them $X, give $X to a high-impact charity (whether or not I also give money to the individual who asked).’ Leah Libresco and Michael Blume make good use of this kind of ‘nudged giving’.
But I think we should also normalize whimsical, untriggered high-impact giving. If we start thinking of evidence-based humanitarianism as the kind of thing you can splurge on, I suspect we’ll come to see do-gooding as more of a fun opportunity and less of a burden.
Some people think of their philanthropy as a personal passion that drives them to excel, as in Holden Karnofsky’s “excited altruism“. Others think of their philanthropy as a universal moral obligation they’re striving to meet, as in Eliezer’s “one life against the world“. Try to fit all philanthropists into the ‘passion’ box, and you’ll get a contingent that feels cut off from what makes this work important; try to fit them all into the ‘obligation’ box, and you’ll get a contingent that feels burdened with a dour or guilt-inducing chore.
Likewise, there are important points of divergence between do-gooders who are motivated by different kinds of warm fuzzy (or hot blazing, or cool gliding, or wiggly sparkling…) feelings. I’m more of an obligation-based altruist, but I still find the ‘excited altruist’ framing useful. That I think in moralistic terms doesn’t say much about the specific feelings that drive me to do good in the moment.
Infectious altruism
My moralism also leaves open what feelings I should emphasize if I want to transfer my enthusiasm to others.
The ice bucket challenge is an example of memetically successful Chaos Altruism. Ditto today’s Giving Tuesday event, though an annual event is relatively compatible with the reign of Order. WillMcAskill and TimothyOgden have criticized these memes as possibly counterproductive, but it’s not obvious to me that the ineffectiveness of these events stems from their viral or ad-hoc character. Instead, those same attributes could be very valuable if they were targeted at more urgent causes.
McAskill and Ogden draw attention to the fact that charitable donations have been stuck at 2% of U.S. GDP for 40 years now. People (on average) seem to change where they donate, but not how much they donate. One approach to doing better, than, would be to redirect that 2% to worthier interventions.
At the same time, the success of the giving pledge shows that some people can be inspired to increase their donations. Perhaps we haven’t been able to rise above 2% because charities are too busy competing with each other to focus their advertising ingenuity on growing the pie. Perhaps some deep change in people’s mindset is needed; I’ll note that households giving to religious nonprofits donate twice as much. Relatedly, the key may be to shift entire (small) communities to giving more, so giving more is the norm among everyone you know. Then expand those supergiver tribes into neighboring social networks.
Experimenting with playful, unorthodox, and personalized modes of altruism seems like it could be useful for finding ways to make inroads in new communities. Over the next few years, I think we should place more focus on self-experimentation and object-level research than on outreach; but we should still keep in mind that we need a better handle on human motivation if we’re going to completely restructure the way charity is done. For that reason, I’m eager to hear whether any aspiring effective altruists find Chaos approaches attractive.
Vegans: If the meat eaters believed what you did about animal sentience, most of them would be vegans, and they would be horrified by their many previous murders. Your heart-wrenching videos aren’t convincing to them because they aren’t already convinced that animals can feel.
Meat-eaters: Vegans think there are billions of times more people on this planet than you do, they believe you’re eating a lot of those people, and they care about every one of them the way you care about every human. […]
Finally, let me tell you about what happens when you post a heart-wrenching video of apparent animal suffering: It works, if the thing you’re trying to do is make me feel terrible. My brain anthropomorphizes everything at the slightest provocation. Pigs, cows, chickens, mollusks, worms, bacteria, frozen vegetables, and even rocks. And since I know that it’s quite easy to get me to deeply empathize with a pet rock, I know better than to take those feelings as evidence that the apparently suffering thing is in fact suffering. If you posted videos of carrots in factory farms and used the same phrases to describe their miserable lives and how it’s all my fault for making the world this terrible place where oodles of carrots are murdered constantly, I’d feel the same way. So these arguments do not tend to be revelatory of truth.
I’ve argued before that non-human animals’ abilities to self-monitor, learn, collaborate, play, etc. aren’t clear evidence that they have a subjective, valenced point of view on the world. Until we’re confident we know what specific physical behaviors ‘having a subjective point of view’ evolved to produce — what cognitive problem phenomenal consciousness solves — we can’t confidently infer consciousness from the overt behaviors of infants, non-human animals, advanced AI, anesthetized humans, etc.
[I]f you work on AI, and have an intuition that a huge variety of systems can act ‘intelligently’, you may doubt that the linkage between human-style consciousness and intelligence is all that strong. If you think it’s easy to build a robot that passes various Turing tests without having full-fledged first-person experience, you’ll also probably (for much the same reason) expect a lot of non-human species to arrive at strategies for intelligently planning, generalizing, exploring, etc. without invoking consciousness. (Especially if [you think consciousness is very complex]. Evolution won’t put in the effort to make a brain conscious unless it’s extremely necessary for some reproductive advantage.)
That said, I don’t think any of this is even superficially an adequate justification for torturing, killing, and eating human infants, intelligent aliens, or cattle.
The intellectual case against meat-eating is pretty air-tight
To argue from ‘we don’t understand the cognitive basis for consciousness’ to ‘it’s OK to eat non-humans’ is acting as though our ignorance were positive knowledge we could confidently set down our weight on. Even if you have a specific cognitive model that predicts ‘there’s an 80% chance cattle can’t suffer,’ you have to be just as cautious as you’d be about torturing a 20%-likely-to-be-conscious person in a non-vegetative coma, or a 20%-likely-to-be-conscious alien. And that’s before factoring in your uncertainty about the arguments for your model.
The argument for not eating cattle, chickens, etc. is very simple:
1. An uncertainty-about-animals premise, e.g.: We don’t know enough about how cattle cognize, and about what kinds of cognition make things moral patients, to assign a less-than-1-in-20 subjective probability to ‘factory-farmed cattle undergo large quantities of something-morally-equivalent-to-suffering’.
2. An altruism-in-the-face-of-uncertainty premise, e.g.: You shouldn’t do things that have a 1-in-20 (or greater) chance of contributing to large amounts of suffering, unless the corresponding gain is huge. E.g., you shouldn’t accept $100 to flip a switch that 95% of the time does nothing and 5% of the time nonconsensually tortures an adult human for 20 minutes.
3. An eating-animals-doesn’t-have-enormous-benefits premise.
4. An eating-animals-is-causally-linked-to-factory-farming premise.
5. So don’t eat the animals in question.
This doesn’t require us to indulge in anthropomorphism or philosophical speculation. And Brienne’s updates to her post suggest she now agrees a lot of meat-eaters we know assign a non-negligible probability to ‘cattle can suffer’. (Also, kudos to Brienne on not only changing her mind about an emotionally fraught issue extremely rapidly, but also changing the original post. A lot of rationalists who are surprisingly excellent at updating their beliefs don’t seem to fully appreciate the value of updating the easy-to-Google public record of their beliefs to cut off the spread of falsehoods.)
This places intellectually honest meat-eating effective altruists in a position similar to Richard Dawkins’:
[I’m] in a very difficult moral position. I think you have a very, very strong point when you say that anybody who eats meat has a very, very strong obligation to think seriously about it. And I don’t find any very good defense. I find myself in exactly the same position as you or I would have been — well, probably you wouldn’t have been, but I might have been — 200 years ago, talking about slavery. […T]here was a time when it was simply the norm. Everybody did it. Some people did it with gusto and relish; other people, like Jefferson, did it reluctantly. I would have probably done it reluctantly. I would have sort of just gone along with what society does. It was hard to defend then, yet everybody did it. And that’s the sort of position I find myself in now. […] I live in a society which is still massively speciesist. Intellectually I recognize that, but I go along with it the same way I go along with celebrating Christmas and singing Christmas carols.
Until I see solid counter-arguments — not just counter-arguments to ‘animals are very likely conscious,’ but to the much weaker formulation needed to justify veg(etari)anism — I’ll assume people are mostly eating meat because it’s tasty and convenient and accepted-in-polite-society, not because they’re morally indifferent to torturing puppies behind closed doors.
Why isn’t LessWrong extremely veg(etari)an?
On the face of it, LessWrong ought to be leading the pack in veg(etari)anism. A lot of LessWrong’s interests and values look like they should directly cash out in a concern for animal welfare:
transhumanism and science fiction: If you think aliens and robots and heavily modified posthumans can be moral patients, you should be more open to including other nonhumans in your circle of concern.
superrationality: Veg(etari)anism benefits from an ability to bind my future self to my commitments, and from a Kantian desire to act as I’d want other philosophically inclined people in my community to act.
utilitarianism: Animals causes are admirably egalitarian and scope-sensitive.
taking ideas seriously: If you’re willing to accept inconvenient conclusions even when they’re based in abstract philosophy, that gives more power to theoretical arguments for worrying about animal cognition even if you can’t detect or imagine that cognition yourself.
distrusting the status quo: Veg(etari)anism remains fairly unpopular, and societal inertia is an obvious reason why.
distrusting ad-hoc intuitions: It may not feel desperately urgent to stop buying hot dogs, but you shouldn’t trust that intuition, because it’s self-serving and vulnerable to e.g. status quo bias. This is a lot of how LessWrong goes about ‘taking ideas seriously’; one should ‘shut up and multiply’ even when a conclusion is counter-intuitive.
Yet only about 15% of LessWrong is vegetarian (compared to 4-13% of the Anglophone world, depending on the survey). By comparison, the average ‘effective altruist’ LessWronger donated $2503 to charity in 2013; 9% of LessWrongers have been to a CFAR class; and 4% of LessWrongers are signed up for cryonics (and another 24% would like to be signed up). These are much larger changes relative to the general population, where maybe 1 in 150,000 people are signed up for cryonics.
I can think of a few reasons for the discrepancy:
(a) Cryonics, existential risk, and other LessWrong-associated ideas have techy, high-IQ associations, in terms of their content and in terms of the communities that primarily endorse them. They’re tribal markers, not just attempts to maximize expected utility; and veg(etari)ans are seen as belonging to other tribes, like progressive political activists and people who just want to hug every cat.
(b) Those popular topics have been strongly endorsed and argued for by multiple community leaders appealing to emotional language and vivid prose. It’s one thing to accept cryonics and vegetarianism as abstract arguments, and another thing to actually change your lifestyle based on the argument; the latter took a lot of active pushing and promotion. (The abstract argument is important; but it’s a necessary condition for action, not a sufficient one. You can’t just say ‘I’m someone who takes ideas seriously’ and magically stop reasoning motivatedly in all contexts.)
(c) Veg(etari)anism isn’t weird and obscure enough. If you successfully sign up for cryonics, LessWrong will treat you like an intellectual and rational elite, a rare person who actually thinks clearly and acts accordingly. If you successfully donate 10% of your income to GiveWell, ditto; even though distributing deworming pills isn’t sexy and futuristic, it’s obscure enough (and supported by enough community leaders, per (b)) that it allows you to successfully signal that you’re special. If 10% of the English-speaking world donated to GiveWell or were signed up for cryonics, my guess is that LessWrongers would be too bored by those topics to rush to sign up even if the cryonics and deworming organizations had scaled up in ways that made marginal dollars more effective. Maybe you’d get 20% to sign up for cryonics, but you wouldn’t get 50% or 90%.
(d) Changing your diet is harder than spending lots of money. Where LessWrongers excel, it’s generally via once-off or sporadic spending decisions that don’t have a big impact on your daily life. (‘Successfully employing CFAR techniques’ may be an exception to this rule, if it involves reinvesting effort every single day or permanently skipping out on things you enjoy; but I don’t know how many LessWrongers do that.)
If those hypotheses are right, it might be possible to shift LessWrong types more toward veganism by improving its status in the community and making the transition to veganism easier and less daunting.
What would make a transhumanist excited about this?
I’ll conclude with various ideas for bridging the motivation gap. Note that it doesn’t follow from ‘the gap is motivational’ that posting a bunch of videos of animal torture to LessWrong or the Effective Altruism Forum is the best way to stir people’s hearts. When intellectual achievement is what you trust and prize, you’re more likely to be moved to action by things that jibe with that part of your identity. Write stunningly beautiful, rigorous, philosophically sophisticated things that are amazing and great
I’m not primarily thinking of writing really good arguments for veg(etari)anism; as I noted above, the argument is almost too clear-cut. It leaves very little to talk about in any detail, especially if we want something that hasn’t been discussed to death on LessWrong before. However, there are still topics in the vicinity to address, such as ‘What is the current state of the evidence about the nutrition of veg(etari)an diets?’ Use SlateStarCodex as a model, and do your very best to actually portray the state of the evidence, including devoting plenty of attention to any ways veg(etari)an diets might turn out to be unhealthy. (EDIT: Soylent is popular with this demographic and is switching to a vegan recipe, so it might be especially useful to evaluate its nutritional completeness and promote a supplemented Soylent diet.)
In the long run you’ll score more points by demonstrating how epistemically rational and even-handed you are than by making any object-level argument for veg(etari)anism. Not only will you thereby find out more about whether you’re wrong, but you’ll convince rationalists to take these ideas more seriously than if you gave a more one-sided argument in favor of a policy.
Fiction, done right, can serve a similar function. I could imagine someone writing a sci-fi story set in a future where humans have evolved into wildly different species with different perceived rights, thus translating animal welfare questions into a transhumanist idiom.
Just as the biggest risk with a blog post is of being too one-sided, the biggest risk with a story is of being too didactic and persuasion-focused. The goal is not to construct heavy-handed allegories; the goal is to make an actually good story, with moral conflicts you’re genuinely unsure about. Make things that would be worth reading even if you were completely wrong about animal ethics, and as a side-effect you’ll get people interested in the science, the philosophy, and the pragmatics of related causes. Be positive and concrete
Frame animal welfare activism as an astonishingly promising, efficient, and uncrowded opportunity to do good. Scale back moral condemnation and guilt. LessWrong types can be powerful allies, but the way to get them on board is to give them opportunities to feel like munchkins with rare secret insights, not like latecomers to a not-particularly-fun party who have to play catch-up to avoid getting yelled at. It’s fine to frame helping animals as challenging, but the challenge should be to excel and do something astonishing, not to meet a bare standard for decency.
This doesn’t necessarily mean lowering your standards; if you actually demand more of LessWrongers and effective altruists than you do of ordinary people, you’ll probably do better than if you shot for parity. If you want to change minds in a big way, think like Berwick in this anecdote from Switch:
In 2004, Donald Berwick, a doctor and the CEO of the Institute for Healthcare Improvement (IHI), had some ideas about how to save lives—massive numbers of lives. Researchers at the IHI had analyzed patient care with the kinds of analytical tools used to assess the quality of cars coming off a production line. They discovered that the ‘defect’ rate in health care was as high as 1 in 10—meaning, for example, that 10 percent of patients did not receive their antibiotics in the specified time. This was a shockingly high defect rate—many other industries had managed to achieve performance at levels of 1 error in 1,000 cases (and often far better). Berwick knew that the high medical defect rate meant that tens of thousands of patients were dying every year, unnecessarily.
Berwick’s insight was that hospitals could benefit from the same kinds of rigorous process improvements that had worked in other industries. Couldn’t a transplant operation be ‘produced’ as consistently and flawlessly as a Toyota Camry?
Berwick’s ideas were so well supported by research that they were essentially indisputable, yet little was happening. He certainly had no ability to force any changes on the industry. IHI had only seventy-five employees. But Berwick wasn’t deterred.
On December 14, 2004, he gave a speech to a room full of hospital administrators at a large industry convention. He said, ‘Here is what I think we should do. I think we should save 100,000 lives. And I think we should do that by June 14, 2006—18 months from today. Some is not a number; soon is not a time. Here’s the number: 100,000. Here’s the time: June 14, 2006—9 a.m.’
The crowd was astonished. The goal was daunting. But Berwick was quite serious about his intentions. He and his tiny team set out to do the impossible.
IHI proposed six very specific interventions to save lives. For instance, one asked hospitals to adopt a set of proven procedures for managing patients on ventilators, to prevent them from getting pneumonia, a common cause of unnecessary death. (One of the procedures called for a patient’s head to be elevated between 30 and 45 degrees, so that oral secretions couldn’t get into the windpipe.)
Of course, all hospital administrators agreed with the goal to save lives, but the road to that goal was filled with obstacles. For one thing, for a hospital to reduce its ‘defect rate,’ it had to acknowledge having a defect rate. In other words, it had to admit that some patients were dying needless deaths. Hospital lawyers were not keen to put this admission on record.
Berwick knew he had to address the hospitals’ squeamishness about admitting error. At his December 14 speech, he was joined by the mother of a girl who’d been killed by a medical error. She said, ‘I’m a little speechless, and I’m a little sad, because I know that if this campaign had been in place four or five years ago, that Josie would be fine…. But, I’m happy, I’m thrilled to be part of this, because I know you can do it, because you have to do it.’ Another guest on stage, the chair of the North Carolina State Hospital Association, said: ‘An awful lot of people for a long time have had their heads in the sand on this issue, and it’s time to do the right thing. It’s as simple as that.’
IHI made joining the campaign easy: It required only a one-page form signed by a hospital CEO. By two months after Berwick’s speech, over a thousand hospitals had enrolled. Once a hospital enrolled, the IHI team helped the hospital embrace the new interventions. Team members provided research, step-by-step instruction guides, and training. They arranged conference calls for hospital leaders to share their victories and struggles with one another. They encouraged hospitals with early successes to become ‘mentors’ to hospitals just joining the campaign.
The friction in the system was substantial. Adopting the IHI interventions required hospitals to overcome decades’ worth of habits and routines. Many doctors were irritated by the new procedures, which they perceived as constricting. But the adopting hospitals were seeing dramatic results, and their visible successes attracted more hospitals to join the campaign.
Eighteen months later, at the exact moment he’d promised to return—June 14, 2006, at 9 a.m.—Berwick took the stage again to announce the results: ‘Hospitals enrolled in the 100,000 Lives Campaign have collectively prevented an estimated 122,300 avoidable deaths and, as importantly, have begun to institutionalize new standards of care that will continue to save lives and improve health outcomes into the future.’
The crowd was euphoric. Don Berwick, with his 75-person team at IHI, had convinced thousands of hospitals to change their behavior, and collectively, they’d saved 122,300 lives—the equivalent of throwing a life preserver to every man, woman, and child in Ann Arbor, Michigan.
This outcome was the fulfillment of the vision Berwick had articulated as he closed his speech eighteen months earlier, about how the world would look when hospitals achieved the 100,000 lives goal:
‘And, we will celebrate. Starting with pizza, and ending with champagne. We will celebrate the importance of what we have undertaken to do, the courage of honesty, the joy of companionship, the cleverness of a field operation, and the results we will achieve. We will celebrate ourselves, because the patients whose lives we save cannot join us, because their names can never be known. Our contribution will be what did not happen to them. And, though they are unknown, we will know that mothers and fathers are at graduations and weddings they would have missed, and that grandchildren will know grandparents they might never have known, and holidays will be taken, and work completed, and books read, and symphonies heard, and gardens tended that, without our work, would have been only beds of weeds.’
As an added bonus, emphasizing excellence and achievement over guilt and wickedness can decrease the odds that you’ll make people feel hounded or ostracized for not immediately going vegan. I expressed this worry in Virtue, Public and Private, e.g., for people with eating disorders that restrict their dietary choices. This is also an area where ‘just be nice to people’ is surprisingly effective.
If you want to propagate a modest benchmark, consider: “After every meal where you eat an animal, donate $1 to the Humane League.” Seems like a useful way to bootstrap toward veg(etari)anism, and it fits the mix of economic mindfulness and virtue cultivation that a lot of rationalists find appealing. This sort of benchmark is forgiving without being shapeless or toothless. If you want to propagate an audacious vision for the future, consider: “There were 1200 meat-eaters on LessWrong in the 2013 survey; if we could get them to consume 30% less meat from land animals over the next 10 years, we could prevent 100,000 deaths (mostly chickens). Let’s shoot for that.” Combining an audacious vision with a simple, actionable policy should get the best results. Embrace weird philosophies
Here’s an example of the special flavor LessWrong-style animal activism could develop:
Are there any animal welfare groups that emphasize the abyssal otherness of the nonhuman mind? That talk about the impossible dance, the catastrophe of shapeless silence that lies behind a cute puppy dog’s eyes? As opposed to talking about how ‘sad’ or ‘loving’ the puppies are?
I think I’d have a much, much easier time talking about the moral urgency of animal suffering without my Anthropomorphism Alarms going off if I were part of a community like ‘Lovecraftians for the Ethical Treatment of Animals’.
This is philosophically sound and very relevant, since our uncertainty about animal cognition is our best reason to worry about their welfare. (This is especially true when we consider the possibility that non-humans might suffer more than any human can.) And, contrary to popular misconceptions, the Lovecraftian perspective is more about profound otherness than about nightmarish evil. Rejecting anthropomorphism makes the case for veg(etari)anism stronger; and adopting that sort of emotional distance, paradoxically, is the only way to get LessWrong types interested and the only way to build trust.
Yet when I expressed an interest in this nonstandard perspective on animal well-being, I got responses from effective animal altruists like (paraphrasing):
‘Your endorsement of Lovecraftian animal rights sounds like an attack on animal rights; so here’s my defense of the importance of animal rights…’
‘No, viewing animal psychology as alien and unknown is scientifically absurd. We know for a fact that dogs and chickens experience human-style suffering. (David Pearce adds: Also lampreys!)’
‘That’s speciesist!’
Confidence about animal psychology (in the direction of ‘it’s relevantly human-like’) and extreme uncertainty about animal psychology can both justify prioritizing animal welfare; but when you’re primarily accustomed to seeing uncertainty about animal psychology used as a rationalization for neglecting animals, it will take increasing amounts of effort to keep the policy proposal and the question-of-fact mentally distinct. Encourage more conceptual diversity and pursue more lines of questioning for their own sake, and you end up with a community that’s able to benefit more from cross-pollination with transhumanists and mainline effective altruists and, further, one that’s epistemically healthier.
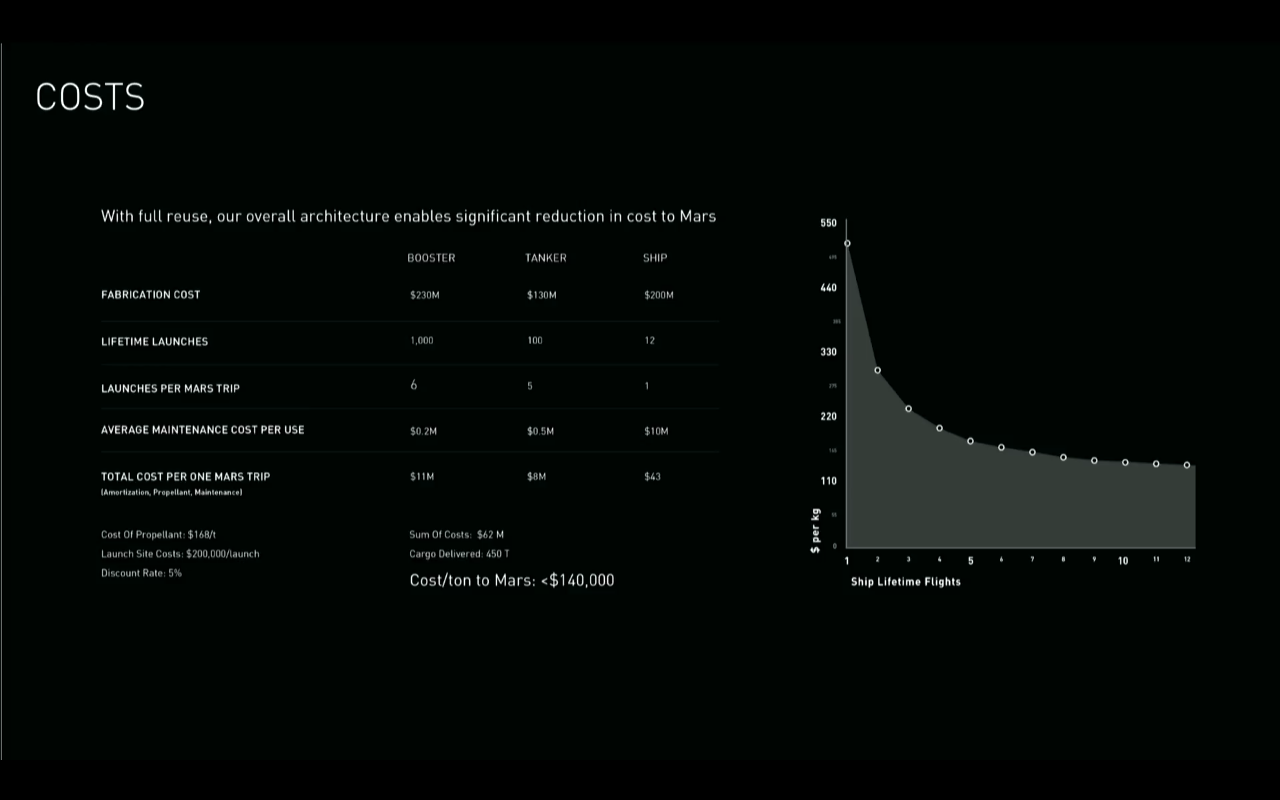

 Back in November, I argued (in
Back in November, I argued (in 






